Personal Project - Automating numerical calculations and implementing ML models
TABLE OF CONTENTS
- 1.Introduction#introduction
- 2.Features#features
- 3.Architecture#architecture
- 3.1.Service#service
- 3.2.API#api
- 3.3.Web Application#web-application
- 3.4.ML-API#ml-api
- 4.Models#models
- 5.How it works#how-it-works
- 5.1.Running Calculations#running-calculations
- 5.2.Authentication and Authorization#authentication-and-authorization
- 5.3.Emails#emails
- 5.4.Analysis#analysis
- 5.5.Multiple clusters#multiple-clusters
Introduction
As technology advances most scientists are looking for ways to use modern solutions in their everyday work. The web is filled with different kinds of tools that can boost the productivity of the whole team and speed-up the research process. Usually those tools are highly specialized for their field of research and require some tech knowledge on how to set them up.
If the research team is vastly invested in numerical analysis and long-running calculations, that means setting up a specialized cluster, compiling all the necessary libraries, and handling updates - which requires some experience1.
Once everything is up and running, most of the time goes into:
- configuring calculations
- copying required files (especially between multiple calculations)
- running calculations
- checking if everything is going well and monitoring resources
- reviewing output data
- confirming that the calculation converged and the output makes sense
- sharing results with the team and comparing it between different calculations etc.
Some of this work can be automated using custom scripts, but that's not a solution that provides high level of automation and frees up the time of scientists to focus on important parts of their research.
Another important topic is ML-hype train, which is taking research papers by storm. Most of research teams are already working on incorporating ML models in their work, but dealing with tech required for training and running models can be daunting for starters. Moreover, experimenting with ML models and training requires easy access to well-structured data, not to mention resources for managing and running models for inference.
Realizing that all of this can be a huge burden and a waste of time for researchers, I've decided to create a personal project in collaboration with a group from the Institute for Multidisciplinary Research in Belgrade. The goal is to create a system that allows scientists to automate numerical calculations and easily integrate ML models for numerical predictions.
This post gives an overview of the system, its features, and how it works. The source code is not available for now. The idea is still in the progress and architecture presented here may change significantly.
If you have any additional questions and suggestions, please don't hesitate to reach out.
Features
This system allows scientists to use a web application to:
- Run calculations
- Monitor cluster resources
- Check calculation configurations and logs
- Review and download analysis reports
- Start and stop ML models
- Use models for predictions etc.
The web application acts as an admin dashboard where a user can create and edit different components. However, it has a hierarchy of permissions: user, moderator, and admin. The main difference is, of course, level of access to certain parts of the dashboard, for example, only admins can manager users etc.
Another important feature are notifications. Instead of constantly checking what's going on with the calculation process, scientists can receive email notifications informing them that calculation was successful and an analysis report is ready, or something went wrong and an error was raised.
All the calculation data and analysis reports are stored in a database. This gives a good overview and provides access to well-structured data for further research, especially for training models.
Training of models is done outside of the system, since that process highly depends on the use case, requirements, and experimentation. However, once the team is satisfied with a model, they can "plug it in", and use it within the system by issuing commands through the web application.
Architecture
The system consists of the following components:
- Numerical Software
- Cluster
- Service
- API
- Database
- Web Application
- ML-API
- Models
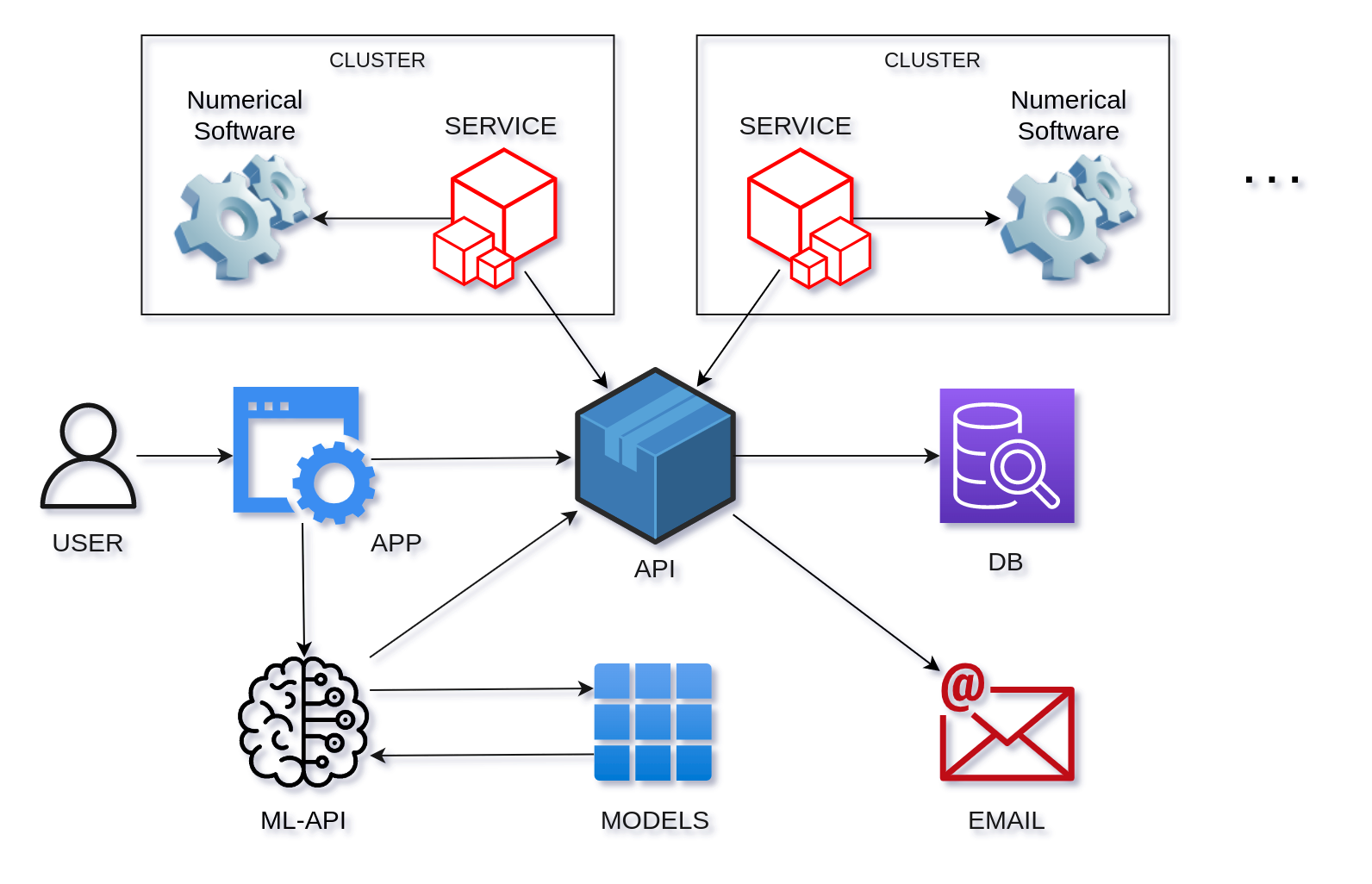
Architecture
Service
Written in Python, runs on a cluster as a background service, communicates with the API, and takes care of the following:
- Cluster heartbeat - Sends information about the cluster's state every X seconds (CPU, memory ...). This data is then graphed in web application for a particular calculation or cluster
- Sets up the folder structure - Manages folder structure for different calculations and copies required files and configurations. If you are familiar with SIESTA, think of .fdf, .psf files etc
- Runs a calculation - Checks API if someone created a calculation and starts calculation process
- Runs multiple calculations - Sometimes calculation run consists of multiple calculations with slightly different configuration. For example, same molecule but different voltage or rotation. In this case, service will create multiple folders for different calculations and run calculations in specific order while copying required files between them (since one calculation depends on the result of another)
- Calculation state - Keeps track of the running calculation and informs API of what's happening. These state updates are used for email notifications
- Validates results - Getting output results doesn't mean that the calculation was successful. Sometimes the process went fine but the calculation didn't converge. Service validates results to prevent cases where further calculations work with "invalid" results
- Extracts data for analysis - Most of the time calculation output results are quite large, in order of gigabytes. Transferring this amount of data is not efficient and actually not needed, since research teams are usually interested in a small subset of those results. Therefore, service can extract and prepare data for further analysis. This data then gets stored in a database and is used for graphs on the frontend side
- Deletes raw files - Since output data is quite large, storage needs to be closely monitored. Keeping raw data files for old calculations doesn't make sense in many cases. Therefore, this service can also clean up calculations folder, keeping extracted data but removing large files of raw data
Some of the things mentioned here are very specific and highly depended on a particular use case. The service currently runs SIESTA and performs a set of analyses defined by the research team I'm collaborating with. However, it can be easily extended to support different numerical software and data preparation steps.
API
Written in Node.js using express.js framework, takes care of the following:
- Receives all kinds of updates from clusters
- Stores/Retrieves data in/from the database
- Manages authentication and authorization for the web application
- Integrates with third party systems for email notifications
- Gets model heartbeat from the ML-API
Web Application
Written in React, serves as a control dashboard, contains the following sections:
- Dashboard - Overview of clusters' state, running calculations...
- Analyses - Calculation reports. Includes graphs, tables...
- Calculations - List of calculations, details, configurations, state...
- Molecules - This is specific for the team that I'm working with, but we have models of molecules which are connected to calculations. So the team can easily see all the calculations for a particular model and compare results.
- Models - List of ML models that are present in the system and their configuration, state, etc... Basically, panel for managing and interacting with models.
- Clusters - Panel for managing clusters
- Logs - Live feed of service logs
- Users - Panel for managing users
The idea behind this web application is to give a user-friendly overview of the whole system where scientists can easily review calculations, set configurations, compare results, download reports, manage models, and use them for predictions.
The aforementioned permissions limit the level of access, for example:
- Only admins can delete logs, manage multiple cluster configurations etc
- Moderators can change users' passwords and block them, but they cannot create or delete them
- Users can view/create/edit everything related to calculations and analyses
ML-API
If you take a closer look at the architecture you'll see that the web application communicates with two APIs. One of them is ML-API this API is written in Python using FastAPI framework, and it takes care of the following:
- Manages ML models - Scientists can run, stop, or delete models
- Interacts with docker engine - Models are implemented as docker images and this API controls them via docker engine
- Model heartbeat - Checks the state of running models and sends it to API
- Proxies inference - Inference calls from a web application are proxied to an appropriate docker container
Models
Experimental phase of training and validating models is done outside of the system. Once the team is satisfied with the results, they can package the model in a docker image and "plug it in".
The docker image has to satisfy certain things. It has to have a server with the following endpoints:
/ping- GET - Responds with 200 if model is loaded and everything is fine/invocations- POST - Receives inference parameters and returns prediction data
The /ping is required for the heartbeat. ML-API periodically checks running
containers and requires 200 status, otherwise it will restart the container.
If you've ever built custom BYOC models for AWS Sagemaker, you'll recognize this pattern. Meaning, you can run the same model in this and different systems.
Check SageMaker Serverless Inference using BYOC for more information
How it works
Running Calculations
Scientist can create a new calculation in the web application by providing
name, description, configuration, choosing a cluster and a set of analyses to be
performed. This will then be stored in the database with processed=False field.
Services, that run on multiple clusters, will query the API asking for
calculations that have processed=False&cluster=XYZ, start with the
process based on the configuration, and mark it as running.
This process is very basic for now, but the plan is to extend it with:
approved- Calculation needs to be approved by moderator or admin before the service can pull it. This would be valuable for larger teams with less experienced researcherspriority- Some basic stuff in order to push one calculation in front of another
Authentication and Authorization
Authentication and authorization is done using JSON web tokens (JWTs). When a user logs in, it will get a refresh token via a cookie and access token which the application stores in memory. Every X minutes the refresh token is used to refresh the access token. This is a standard way to manage JWT and admins can easily disable refresh tokens, if they ever have to.
Another benefit of using JWTs is managing authentication across multiple APIs. For example, ML-API just checks if JWT is provided and valid, it doesn't have to issue or manage tokens.
However, communication between cluster services and API is done using an API key. The keys can be easily changed in the web application and set in configuration files on the clusters' side. The same goes for ML-API.
Emails
The service constantly updates the API and for certain types of events, API will send an email based on the user's configuration. Users can configure INFO or ERROR level of emails. Besides the user who created a calculation, all the admins will get emails as well.
Emails are sent using third party email delivery platforms such as Mailtrap or SendGrid.
Analysis
Once the calculation is done, service will perform a set of analyses on extracted data and send it to the API, this data is then fetched on the frontend application and used to create graphs, tables, charts etc.
Currently, the research team, I'm collaborating with, already has a well-defined set of data analyses they perform each time and the process is straight-forward, but that won't be the case for all teams. In such situations, extending the service can be easily done and web application adjusted to support checkboxes or other selectors.
However, there are cases where analysis_2 depends on the results of
analysis_1 and careful ordering of actions is required. The web application
should make sure that the set of analyses is valid i.e. analysis_2 cannot be
selected without analysis_1 and so on...
Multiple clusters
Some research groups have access to multiple clusters or machines. In that case they can configure the system to work with all of them:
- Add cluster to the system through the web application
- Generate API keys
- Install and configure the service on clusters
- Check logs in UI to see if service is working and connection is established
Having multiple clusters is beneficial when it comes to updates. Numerical software usually needs to be recompiled with updated libraries and that takes time. In such situations, the team can disable the service during the update and enable it once the cluster is ready.
Footnotes
-
Unless they are paying for computation time on some pre-configured cloud cluster, but that is expensive in most cases. ↩