Installing Packages from a Private PyPI Repository on Databricks Clusters
TABLE OF CONTENTS
This blog post is also published on the Databricks Technical Blog.
Introduction
Private repositories are a common way for organizations to manage Python libraries, both internally developed packages and approved third-party dependencies. They provide an additional layer of security by enforcing governance processes such as vulnerability scanning and approval workflows before teams can use external libraries.
In cloud-based enterprise environments, private artifact repositories are typically hosted on managed services like AWS CodeArtifact or Azure DevOps Artifacts. These services simplify access control, auditing, and integration with development workflows.
In this post, we'll focus on Azure DevOps Artifacts and demonstrate how to connect a Databricks cluster to a private PyPI feed in order to install packages. While Azure DevOps is used as the example, the same approach applies to other artifact repository services.
Artifact Feed
Azure Artifacts is a managed and streamlined way for developers to manage all dependencies from a single feed. The feed serves as a repository for storing, managing, and sharing packages. Packages can be shared within the team, across organization or publicly online. You just have to authenticate and connect to the feed in order to pull the packages.
Check the following documentation on how to Create a new Feed.
Once you have an Artifact feed you can connect to it in variety of ways.

Connect to Feed
Azure DevOps Artifacts supports multiple package managers for connecting to a feed, including
NuGet, npm, Maven, Gradle, pip, twine, Cargo etc.
When using pip, the feed provides an index-url in the following format:
index-url=https://pkgs.dev.azure.com/<organization>/<project>/_packaging/<feed>/pypi/simple/
The index-url defines the base URL of a Python package repository. By default, pip looks up
packages from the public PyPI, but with this configuration, it will instead fetch them from
the specified private feed.
You could also specify extra-index-url to add additional package repositories. For more information, please see the official pip documentation.
Since the feed is private, authentication is required. The most straightforward way to authenticate
is by generating a Personal Access Token (PAT) in Azure DevOps and embedding it in the index-url.
index-url=https://{USER}:{PAT}@pkgs.dev.azure.com/<organization>/<project>/_packaging/<feed>/pypi/simple/
This ensures that pip can securely access and install packages from the private repository.
If you are interested in using Service Principal for authentication, please see the following discussion.
In order to test the connection, we can create a virtual environment and just install a package using the following command
pip install --index-url=<url> <package-name>
Keep in mind that your feed may have Upstream Sources enabled. If a package isn't found in your private repository, Azure Artifacts will automatically fall back to searching the upstream source, the public PyPI by default, and store the package in the feed.
Databricks Setup
There are several ways to connect your Databricks workspace to an external private repository, enabling clusters to fetch the necessary packages.
In this article, we'll explore two approaches: configuring the connection at the cluster level and applying the default private repository across the entire workspace.
Cluster Level
Now that we can connect to the feed and fetch packages, the next question is: how do we use this on a Databricks cluster?
For quick experiments, you can install a package directly from a notebook using the pip magic
command:
%pip install --index-url=<url> <package-name>
While this works well for ad-hoc testing, it's not ideal for regular or production workloads.
The installation is tied to the specific notebook, and the index-url is hardcoded in the notebook
itself, making it difficult to maintain and scale across teams or clusters.
For more information, check out the following documentation article - Notebook-scoped Python libraries
A better approach is to configure the cluster's global index-url before it installs any
dependencies. This way, any pip install command, whether run from a notebook or during cluster
startup, will automatically pull packages from your private repository.
To do so, we have to set cluster environment variables, as described in the release notes:
In Databricks Runtime 15.1 and later, you can configure global pip index-url and extra-index-url parameters for cluster and notebook-scoped library installation when configuring a cluster or defining a cluster policy. To do so, set the environment variables DATABRICKS_PIP_INDEX_URL and DATABRICKS_PIP_EXTRA_INDEX_URL.
The extra-index-url tells pip to check an additional package repository for packages it cannot
find in the main index-url.
One great advantage of cluster environment variables is that they can reference secrets stored in Databricks secret scopes. This eliminates the need to hardcode sensitive information and keeps credentials secure. If a token expires, you simply update the secret, new clusters will automatically pick up the refreshed token at startup.
In practice, you can configure a cluster environment variable called
DATABRICKS_PIP_INDEX_URL and point it to the secret that contains your index-url:
DATABRICKS_PIP_INDEX_URL={{secrets/<scope-name>/<secret-name>}}
With this setup, Databricks will automatically use your private repository as the default source for fetching cluster library dependencies at startup.
To confirm that, check cluster logs, it will show redacted index-url and progress of installing
library dependencies at startup.
If you're working with
Databricks Asset Bundles,
you can configure cluster environment variables by setting spark_env_vars in the
cluster configuration.
In the task definition, you can then specify the required libraries, which will be automatically
pulled from your private repository when the task starts.
Workspace Level
Workspace administrators can set private or authenticated package repositories as the default pip configuration for serverless notebooks, serverless jobs, and classic compute within a workspace.
This setting will be applied to all clusters in the workspace by default. However, if you
explicitly define index-url and extra-index-url in code or in a notebook, it will take
precedence over the default values.
To set these default values, please take the following steps:
- As a workspace administrator, log in to the Databricks workspace.
- Click your username in the top bar of the Databricks workspace and select Settings.
- Click on the Compute tab.
- Next to Default Package Repositories, click Manage.
- (Optional) Add or remove an index URL, extra index URLs, or a custom SSL certificate.
- Click Save to save the changes.
The UI settings page
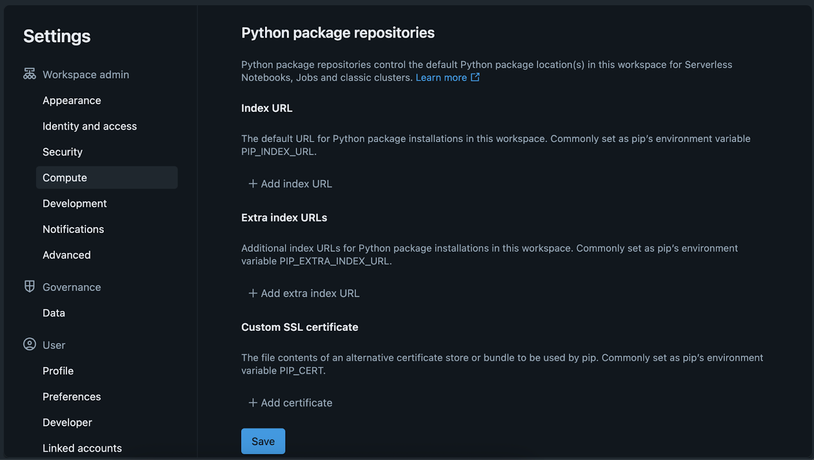
Workspace level private PyPI setup
For more information, please see the official documentation page Set up default dependencies for a workspace.
Conclusion
Managing Python dependencies securely and consistently is critical in enterprise environments, especially when working with multiple teams at scale. By connecting your clusters to a private PyPI repository, you gain tighter control over package sources, improve governance, and reduce the risk of relying on unverified libraries.
To recap:
- In this blog post we covered Azure DevOps Artifacts, but any other artifact service will work as long as it provides a pip feed for packages.
- For production workloads, configure cluster-wide
DATABRICKS_PIP_INDEX_URLcluster environment variable so all package installs default to your private feed. - Store credentials in Databricks secret scopes for security and easier token rotation.
- With Databricks Asset Bundles, leverage
spark_env_varsand tasklibrariesto achieve the same setup in CICD across multiple environments.
By following this setup, your Databricks clusters will seamlessly pull dependencies from a trusted private repository - improving security, governance, and reproducibility.
I hope this helps! If you have any questions or suggestions, please reach out, I'm always available.